Context Engineering in AI: Master Long Context & RAG Systems (2026 Guide)

Large Language Models (LLMs) have become remarkably capable at writing, coding, summarizing, and reasoning. Yet even the most advanced AI systems still produce inaccurate answers, forget earlier instructions, and occasionally generate complete nonsense with surprising confidence. These issues are not simply model problems — they are often context problems.
Modern AI systems rely heavily on the information provided inside their context windows. If the right information is missing, outdated, poorly structured, or overloaded with irrelevant data, the model’s output quality drops quickly. This is why AI accuracy problems such as hallucinations, inconsistent reasoning, irrelevant responses, and poor memory retention continue to appear even in state-of-the-art models.
For years, developers focused primarily on prompt engineering — carefully crafting prompts to guide model behavior. But as AI applications became more complex, prompts alone stopped being enough. Today, the industry is shifting toward a broader and more powerful concept known as context engineering.
Context engineering focuses on managing everything the model sees before generating a response. Instead of relying on a single static prompt, developers now build intelligent systems that dynamically retrieve, filter, compress, rank, and inject relevant information into the model’s context. This evolution has become essential for enterprise AI assistants, coding copilots, research agents, and large-scale automation systems.
At the center of this transformation are AI context windows and long-context optimization techniques. Newer models from companies like OpenAI, Anthropic, and Google can process massive amounts of information at once, but larger context windows also introduce new challenges: token overflow, context dilution, slower inference, and rising computational costs.
Table of Contents
- What Is Context Engineering?
- Understanding Long Context Windows in AI Models
- What Are RAG Systems?
- Context Engineering vs RAG Systems
- Token Optimization Strategies for AI Systems
- Advanced Context Engineering Techniques
- Common Problems in Long Context & RAG Systems
- Best Practices for Context Engineering
- Real-World Use Cases of Context Engineering
- Future of Context Engineering in AI
- Summary
- FAQ Section
To solve these limitations, developers increasingly combine long-context models with Retrieval-Augmented Generation (RAG) systems that fetch external knowledge in real time. Together, these technologies are redefining how modern AI systems handle memory, reasoning, and knowledge retrieval — making context engineering one of the most important emerging disciplines in artificial intelligence today.
What Is Context Engineering?
As AI systems become more sophisticated, developers are realizing that model performance depends less on clever prompting alone and more on how information is organized, retrieved, prioritized, and delivered to the model. This shift has given rise to a new discipline called context engineering — a foundational concept for building reliable, scalable, and intelligent AI systems.
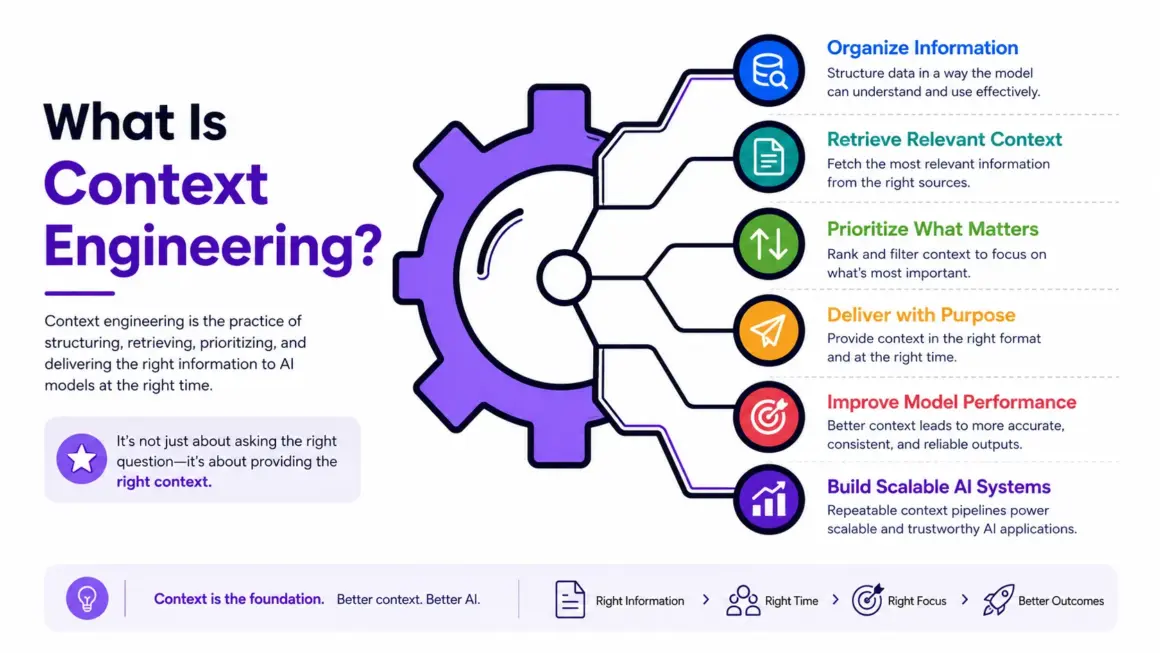
At its core, context engineering is the process of designing and managing the information environment that an AI model uses to generate responses. Instead of focusing only on writing better prompts, context engineering focuses on controlling everything the model sees before inference.
This includes:
- Retrieved documents
- Conversation history
- Memory layers
- System instructions
- User preferences
- External APIs
- Real-time data sources
- Tool outputs
- Structured knowledge
In simple terms, prompt engineering asks:
“What should I ask the model?”
Context engineering asks:
“What information should the model have access to before answering?”
That distinction is extremely important.
Traditional prompt engineering works well for isolated tasks like generating text, summarizing articles, or answering straightforward questions. But modern AI applications are far more complex. Enterprise assistants, autonomous AI agents, coding copilots, and research systems need persistent memory, external knowledge retrieval, multi-step reasoning, and dynamic decision-making.
This is where AI context management becomes critical.
A context-engineered system intelligently selects the most relevant information, removes unnecessary noise, compresses large inputs, and injects contextual knowledge at the right moment. The result is better accuracy, improved consistency, lower hallucination rates, and more reliable long-form reasoning.
In many ways, context engineering can be viewed as the next generation of advanced prompt engineering — one that operates at the system architecture level rather than just the prompt level.
Why Context Matters in LLMs
To understand why context engineering matters, it helps to understand how Large Language Models process information.
LLMs do not “think” like humans. They process text as sequences of tokens, which are small chunks of language such as words, subwords, or characters. Every interaction with a model exists inside a limited LLM context window, meaning the model can only “see” a certain number of tokens at once.
Once that limit is exceeded, older information may be truncated, compressed, or ignored entirely.
This creates several challenges:
- Models may forget earlier instructions
- Long conversations lose coherence
- Important facts disappear from memory
- Irrelevant information competes for attention
- Token limits increase inference costs
The underlying reason comes from the transformer attention mechanism used in modern AI architectures. Attention allows models to determine which parts of the input are most relevant when generating the next token. However, as context grows larger, attention becomes computationally expensive and less efficient.
This often leads to the well-known “lost-in-the-middle” problem, where models pay less attention to information buried deep inside long contexts.
In other words, bigger context windows alone do not automatically solve AI accuracy problems. The quality, relevance, and structure of the context matter just as much as the size.
Evolution from Prompt Engineering to Context Engineering
The AI industry is rapidly evolving from static prompting toward dynamic contextual systems.
Early AI workflows relied heavily on carefully written prompts manually crafted by users. While effective for simple tasks, static prompts struggle in real-world environments where information changes constantly.
Modern AI systems now combine multiple contextual inputs dynamically, including:
- Retrieval-Augmented Generation (RAG)
- Vector database search
- Real-time web retrieval
- Persistent memory systems
- User behavior history
- Tool execution results
- Enterprise knowledge bases
This transition represents the shift from prompt engineering vs context engineering.
Instead of sending a single fixed instruction, AI systems now orchestrate information from many sources before generating an answer. This dramatically improves personalization, factual accuracy, reasoning quality, and workflow automation.
For enterprise environments especially, context engineering has become a core layer of AI workflow optimization, enabling AI systems to function more like intelligent operating systems rather than standalone chatbots.
Understanding Long Context Windows in AI Models
As AI systems evolve, one of the biggest competitive advantages among modern Large Language Models (LLMs) is their ability to handle increasingly larger context windows. Models are no longer limited to short conversations or small text snippets. Today’s advanced systems can process massive documents, long chat histories, code repositories, research papers, and enterprise databases within a single interaction.
But larger context windows are not a perfect solution. They introduce new engineering challenges related to cost, speed, memory efficiency, and information prioritization. Understanding how long-context AI systems work is essential for building scalable and reliable AI applications.
What Is a Context Window?
A context window refers to the maximum amount of text an AI model can process at one time. Everything inside this window becomes the model’s working memory during inference.
This includes:
- User prompts
- System instructions
- Previous conversation history
- Retrieved documents
- External knowledge
- Tool outputs
The size of the context window is measured in AI tokens, not words. Tokens are smaller units of text that may represent full words, partial words, punctuation, or symbols. On average, one token is roughly equivalent to 0.75 words in English, though the exact ratio varies.
For example:
- 1,000 tokens ≈ 750 words
- 100,000 tokens ≈ a short book
- 1 million tokens ≈ several large documents combined
Modern long context models have expanded these limits dramatically. Earlier GPT models handled only a few thousand tokens, while newer systems from companies like OpenAI, Anthropic, and Google now support context windows reaching hundreds of thousands — and in some cases millions — of tokens.
This expansion changes what AI systems can do. Instead of analyzing isolated snippets, models can now reason across entire legal contracts, software repositories, research archives, medical histories, or enterprise knowledge systems in a single workflow.
However, larger context windows do not automatically guarantee better reasoning or accuracy.
Challenges of Large Context Windows
While long-context systems sound impressive, they introduce several serious technical limitations.
One of the most well-known issues is the lost-in-the-middle problem. As context windows become larger, models often pay less attention to information buried in the middle of the input. Important details may exist inside the context but still get ignored during response generation.
This happens because transformer-based architectures distribute attention unevenly across long token sequences.
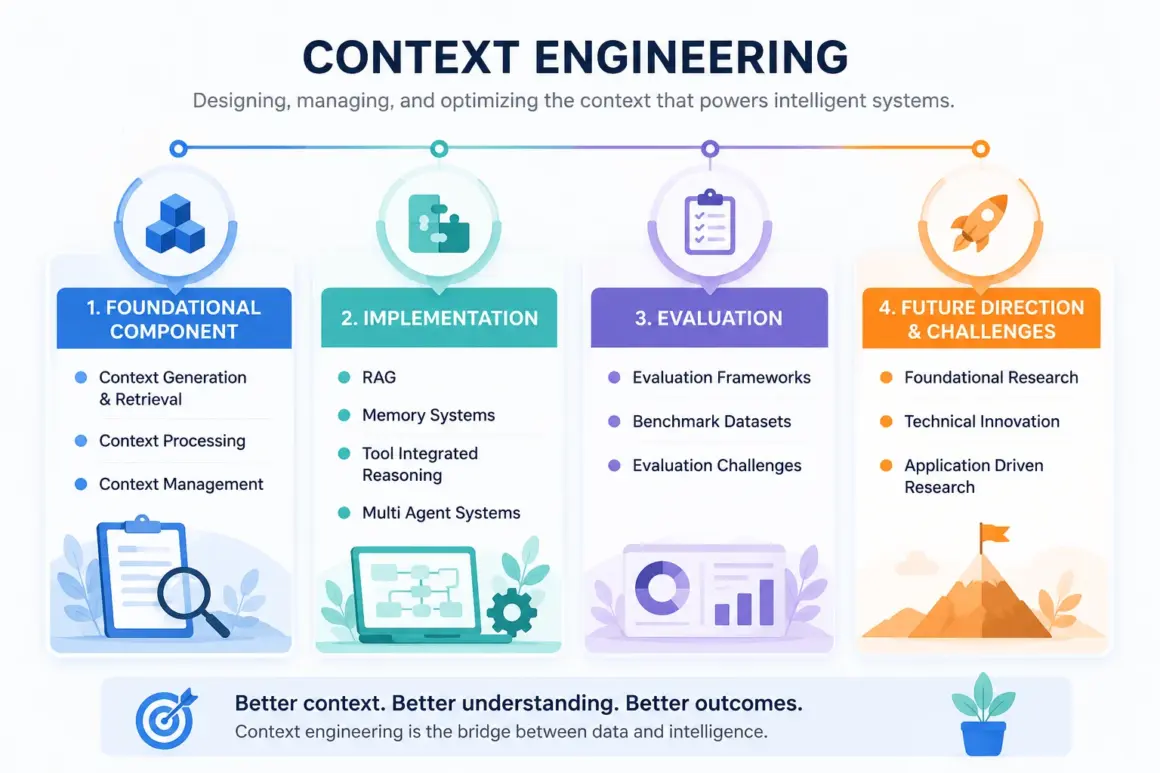
Another major issue is token inefficiency. Larger contexts require significantly more computational resources during inference. Every additional token increases processing complexity, memory consumption, and latency.
In practical terms, this creates three major problems:
- Higher inference costs
- Slower response generation
- Increased infrastructure requirements
For enterprise-scale AI systems handling thousands of users simultaneously, these costs become extremely important.
Long contexts also create context dilution. When too much information is packed into the model window, relevant signals compete against irrelevant noise. The model may struggle to determine which information actually matters.
This often leads to:
- Irrelevant answers
- Reduced reasoning quality
- Lower factual precision
- Increased hallucinations
Another hidden problem is noise accumulation. Long conversational histories frequently contain outdated instructions, contradictory information, repeated content, or irrelevant interactions. Over time, this contaminates the context and reduces overall model reliability.
These long context challenges explain why context engineering is becoming so important. Developers cannot simply “add more tokens” and expect better AI performance. Intelligent filtering, retrieval, ranking, summarization, and orchestration are now essential.
Benefits of Long Context AI Systems
Despite these challenges, long-context AI systems unlock capabilities that were previously impossible.
One of the biggest advantages is improved memory retention. Models can maintain awareness across longer conversations, enabling more coherent interactions and better continuity in complex workflows.
This is especially valuable for:
- AI assistants
- Coding copilots
- Research systems
- Customer support automation
- Enterprise knowledge platforms
Long contexts also enable powerful document intelligence capabilities. AI systems can analyze entire reports, contracts, books, research papers, or technical documentation without aggressive truncation.
For enterprises, this creates opportunities for large-scale internal knowledge retrieval systems where employees can interact conversationally with massive organizational data repositories.
Another major advantage is improved multi-step reasoning. When more relevant information fits inside the context window, models can connect ideas across multiple sources more effectively.
Examples include:
- Repository-level code understanding
- Financial document analysis
- Legal reasoning across contracts
- Scientific literature synthesis
- Multi-document summarization
However, successful long context optimization requires more than just bigger windows. The future of advanced AI systems will depend on how intelligently they manage, prioritize, compress, and retrieve information inside those windows.
This is exactly why context engineering and Retrieval-Augmented Generation (RAG) are becoming foundational components of modern enterprise AI architecture.
What Are RAG Systems?
As Large Language Models become more powerful, one major limitation still remains: they cannot reliably remember or access real-time external knowledge on their own. Even advanced models are restricted by training cutoffs, limited memory, and context window constraints. This is where RAG systems have become one of the most important innovations in modern AI architecture.
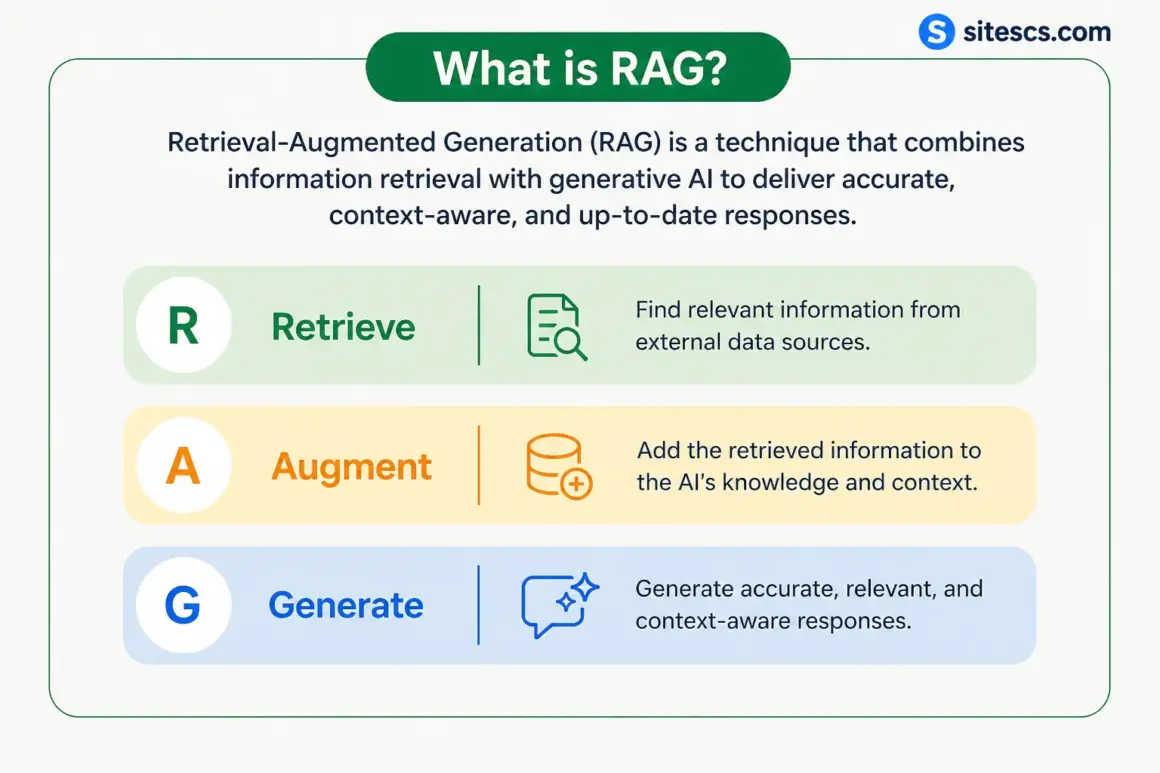
Retrieval-Augmented Generation (RAG) combines information retrieval with text generation, allowing AI systems to fetch relevant knowledge dynamically before producing an answer. Instead of relying only on what the model learned during training, RAG systems give AI access to external documents, databases, APIs, and enterprise knowledge sources in real time.
Today, most production-grade AI assistants, enterprise copilots, and intelligent search systems rely heavily on retrieval pipelines to improve factual accuracy and reduce hallucinations.
RAG Explained Simply
Retrieval-Augmented Generation (RAG) is an AI architecture that enhances language models by retrieving relevant information from external sources before generating a response.
The workflow is surprisingly simple:
- A user asks a question
- The system searches external knowledge sources
- Relevant information is retrieved
- The retrieved context is inserted into the model prompt
- The LLM generates an answer using that information
In other words, the AI does not rely purely on memory. It “looks things up” before responding.
A useful real-world analogy is an open-book exam.
A standard LLM works like a student answering entirely from memory. Sometimes the student remembers correctly. Sometimes they confidently guess and get things wrong.
A RAG-enabled AI system behaves more like a student who can quickly search textbooks, notes, and reference materials before answering. This dramatically improves reliability and factual grounding.
That is why retrieval augmented generation has become a foundational layer for modern AI retrieval systems.
Instead of training giant models repeatedly on constantly changing data, developers can simply update the external knowledge source while keeping the model itself unchanged. This makes AI systems more scalable, flexible, and cost-efficient.
How RAG Architecture Works
Under the hood, RAG systems combine several technologies working together in a pipeline.
The first major component is embeddings.
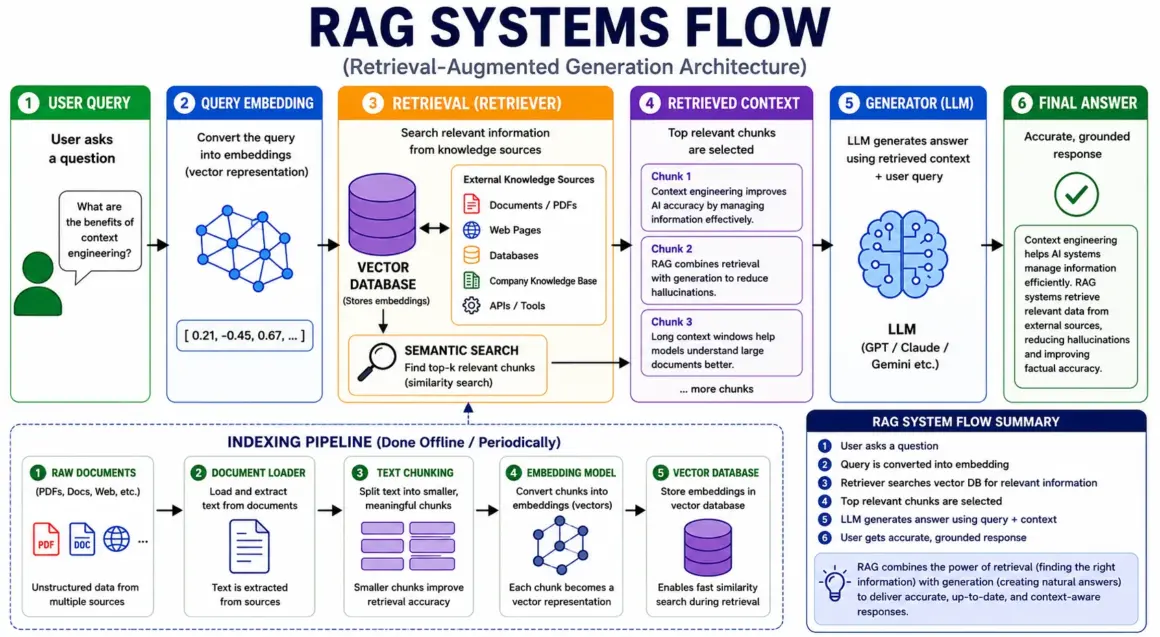
Embeddings are numerical vector representations of text. They convert words, sentences, or documents into mathematical representations that capture semantic meaning rather than exact keyword matching.
For example, phrases like:
- “How do airplanes fly?”
- “Explain aircraft lift”
may use different words but produce similar embeddings because they share related meaning.
These embeddings are stored inside a vector database, which is optimized for similarity search at scale.
Popular vector databases include:
- Pinecone
- Weaviate
- Chroma
- Meta’s FAISS library
When a user submits a query, the system converts the query into an embedding and performs semantic retrieval against the vector database.
Unlike traditional keyword search, semantic search focuses on meaning and contextual similarity.
The pipeline usually works like this:
- User submits a query
- Query is converted into embeddings
- Vector database retrieves semantically relevant chunks
- Retrieved content is ranked and filtered
- Context is injected into the prompt
- The generator model produces the final response
This retriever + generator architecture is the core foundation of modern RAG systems.
In many enterprise environments, retrieval pipelines may also include:
- Metadata filtering
- Hybrid keyword + semantic search
- Re-ranking models
- Context compression
- Multi-step retrieval orchestration
These layers improve retrieval precision and reduce irrelevant context injection.
Why RAG Improves AI Accuracy
One of the biggest advantages of RAG systems is hallucination reduction.
Traditional LLMs sometimes generate answers that sound convincing but are factually incorrect because they rely on probabilistic prediction rather than verified knowledge retrieval.
RAG improves this by grounding responses in external information sources.
Instead of “guessing,” the model receives factual reference material before generating an answer. This leads to more reliable and factual AI responses, especially in knowledge-intensive domains like:
- Healthcare
- Legal research
- Software engineering
- Scientific analysis
- Enterprise documentation
Another major advantage is access to updated information.
LLMs trained months ago may not know recent events, newly published research, or internal company documents. RAG systems solve this through external knowledge retrieval, allowing models to access fresh data without retraining.
This flexibility is extremely valuable for businesses building AI assistants connected to:
- Internal knowledge bases
- Customer support documentation
- Real-time analytics
- Compliance databases
- Product catalogs
- Research repositories
Most importantly, RAG shifts AI systems from static memory toward dynamic knowledge access — a critical step toward building more trustworthy, scalable, and enterprise-ready AI applications.
Context Engineering vs RAG Systems
As AI systems become more advanced, many people use the terms Context Engineering and RAG systems interchangeably. While they are closely related, they are not the same thing.
Understanding the difference is important because modern AI applications rarely rely on retrieval alone. They require intelligent memory management, orchestration, ranking, filtering, compression, and dynamic reasoning across multiple information sources.
In simple terms, RAG is a component, while context engineering is the broader architecture that manages how information flows through an AI system.
Understanding the Relationship
A RAG system focuses mainly on retrieving relevant information from external sources and supplying it to a language model during generation.
Its primary responsibilities include:
- Searching knowledge bases
- Retrieving relevant document chunks
- Performing semantic search
- Injecting retrieved content into prompts
RAG systems are highly effective for improving factual grounding and reducing hallucinations. However, retrieval alone does not solve every AI accuracy problem.
This is where context engineering becomes much broader.
Context engineering manages the entire lifecycle of contextual information inside an AI system. It determines:
- What information should enter the model
- Which memories should persist
- What should be compressed or removed
- How token budgets are allocated
- Which retrieval sources should be prioritized
- How multiple AI agents share memory
- When external tools should be invoked
In other words, RAG is one mechanism used within a larger context orchestration framework.
Modern enterprise AI systems often combine:
- RAG pipelines
- Long-term memory systems
- Session memory
- User personalization layers
- Tool outputs
- Real-time APIs
- Multi-agent coordination
- Context compression engines
All of these components work together under the umbrella of context engineering.
Why the Difference Matters
A retrieval-only architecture may still fail if the system injects irrelevant information, exceeds token limits, or lacks memory prioritization.
For example:
- A chatbot may retrieve correct documents but forget earlier user instructions
- An AI coding assistant may retrieve repository files but lose architectural context
- An enterprise assistant may access company data but fail to prioritize relevant knowledge
This is why advanced AI memory systems now focus heavily on orchestration layers that intelligently manage context flow rather than relying only on retrieval pipelines.
The future of enterprise AI will likely depend more on context orchestration quality than on raw model size alone.
| Feature | Context Engineering | RAG Systems |
|---|---|---|
| Goal | Manage context intelligently | Retrieve relevant information |
| Scope | Broad system architecture | Retrieval-focused |
| Primary Function | Context management and orchestration | External knowledge retrieval |
| Memory Handling | Advanced persistent memory systems | Moderate retrieval memory |
| Token Optimization | High | Medium |
| Data Sources | Multi-source contextual systems | Primarily searchable knowledge bases |
| Personalization | Strong support | Limited support |
| Orchestration Layers | Core component | Usually external |
| Role in AI Systems | Full AI workflow coordination | Retrieval subsystem |
Ultimately, the debate around context engineering vs RAG is not about choosing one over the other. Instead, modern AI systems use RAG as a foundational retrieval layer inside a much larger context-aware architecture designed for scalability, reasoning quality, and intelligent memory management.
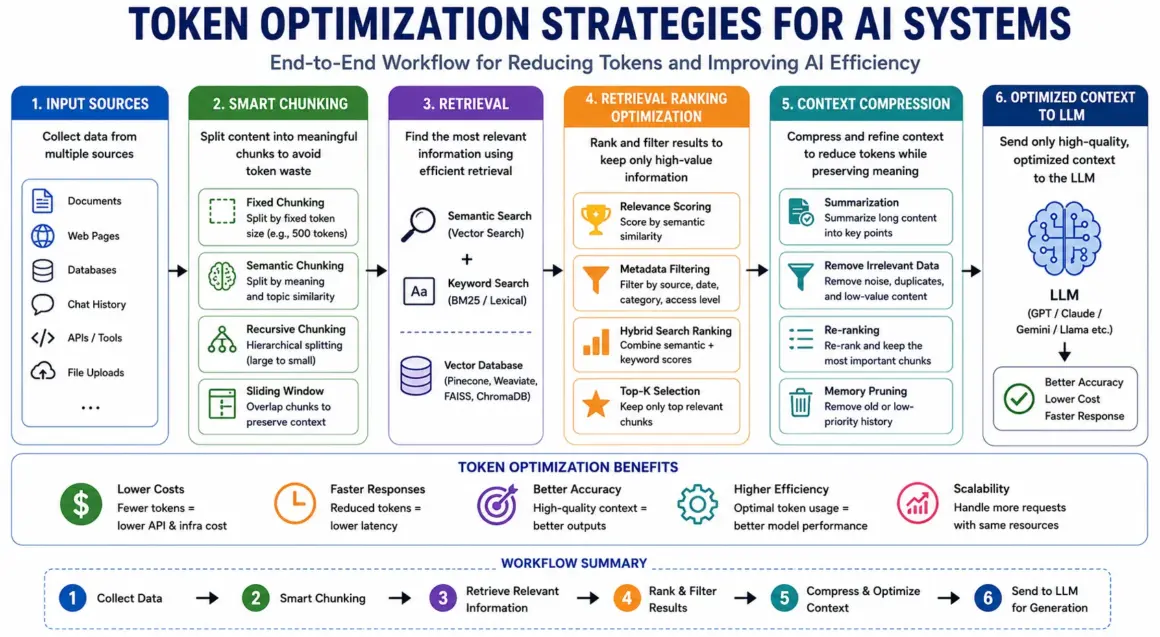
Token Optimization Strategies for AI Systems
As AI applications scale, one challenge becomes impossible to ignore: tokens are expensive. Every prompt, retrieved document, memory layer, and generated response consumes computational resources. In long-context systems and Retrieval-Augmented Generation (RAG) pipelines, inefficient token usage can dramatically increase latency, infrastructure costs, and response inconsistency.
This is why token optimization has become a critical part of modern AI architecture. The goal is not simply to reduce tokens, but to maximize information quality per token used.
Why Token Optimization Matters
Large Language Models process information token by token, and every additional token increases inference complexity. In production AI systems handling millions of requests, token inefficiency quickly becomes a financial and engineering problem.
One major issue is AI inference cost. Most commercial LLM APIs charge based on input and output tokens. Long prompts, oversized retrieval chunks, and unnecessary conversation history can significantly increase operational expenses.
Latency is another major concern.
Larger contexts require more computation during transformer attention processing, leading to slower response generation. For real-time AI assistants, enterprise copilots, and customer support systems, even small delays negatively affect user experience.
Efficient token usage also improves overall LLM efficiency. Cleaner, more relevant context allows models to focus attention on meaningful information instead of wasting computation on noise.
In practice, token optimization improves:
- Response speed
- Retrieval precision
- Context relevance
- Infrastructure scalability
- Memory management
- Hallucination reduction
This is why advanced AI systems aggressively optimize how information enters the context window.
Smart Chunking Techniques
One of the most important optimization methods in AI document processing is text chunking.
Since LLMs cannot efficiently process massive documents all at once, content is divided into smaller chunks before retrieval.
The simplest approach is fixed chunking, where documents are split into equal token lengths such as 500 or 1,000 tokens. While easy to implement, this method often breaks semantic meaning in the middle of paragraphs or concepts.
A more advanced technique is semantic chunking.
Instead of splitting based purely on token count, semantic chunking divides content according to meaning, topic boundaries, sentence structure, or contextual coherence. This improves retrieval quality because chunks remain logically connected.
Another powerful method is recursive chunking, which splits documents hierarchically. Large sections are broken into smaller subsections only when necessary, preserving broader context while maintaining retrieval flexibility.
Some systems also use sliding window techniques, where overlapping chunks preserve continuity between adjacent sections. This reduces information loss during retrieval and improves long-document reasoning.
Effective chunking directly impacts retrieval accuracy, token efficiency, and overall system performance.
Context Compression Methods
As AI systems scale, raw retrieval alone becomes inefficient. This creates the need for intelligent context compression.
One common approach is AI-powered summarization. Instead of injecting entire documents into the prompt, systems generate compact summaries that preserve the most important information while dramatically reducing token usage.
Re-ranking is another important strategy.
After retrieval, multiple chunks may appear relevant. Re-ranking models prioritize the highest-quality results and remove weaker matches before context injection. This improves signal quality inside the prompt window.
Systems also improve performance by filtering irrelevant or redundant information. Duplicate chunks, outdated instructions, and low-value context can dilute model attention and reduce answer quality.
Advanced architectures even use memory pruning, where older conversational data is compressed, archived, or selectively removed based on relevance scores.
These token reduction techniques help maintain high-quality context without overwhelming the model.
Retrieval Ranking Optimization
Efficient retrieval is not only about finding information — it is about finding the right information.
Modern RAG systems increasingly rely on hybrid search, which combines semantic retrieval with traditional keyword-based ranking. This improves precision for technical queries, exact terminology, and structured enterprise data.
Metadata filtering further improves retrieval quality by narrowing searches based on document type, timestamps, departments, permissions, or relevance categories.
Finally, advanced retrieval ranking systems use semantic relevance scoring to prioritize context most likely to improve generation accuracy.
In modern AI systems, smarter retrieval often matters more than larger context windows alone.
Advanced Context Engineering Techniques
As AI systems evolve from simple chatbots into autonomous assistants and multi-agent reasoning systems, basic prompting and retrieval methods are no longer enough. Modern enterprise AI requires sophisticated mechanisms for memory management, contextual coordination, real-time retrieval, and intelligent orchestration across multiple systems.
This is where advanced context engineering techniques become essential.
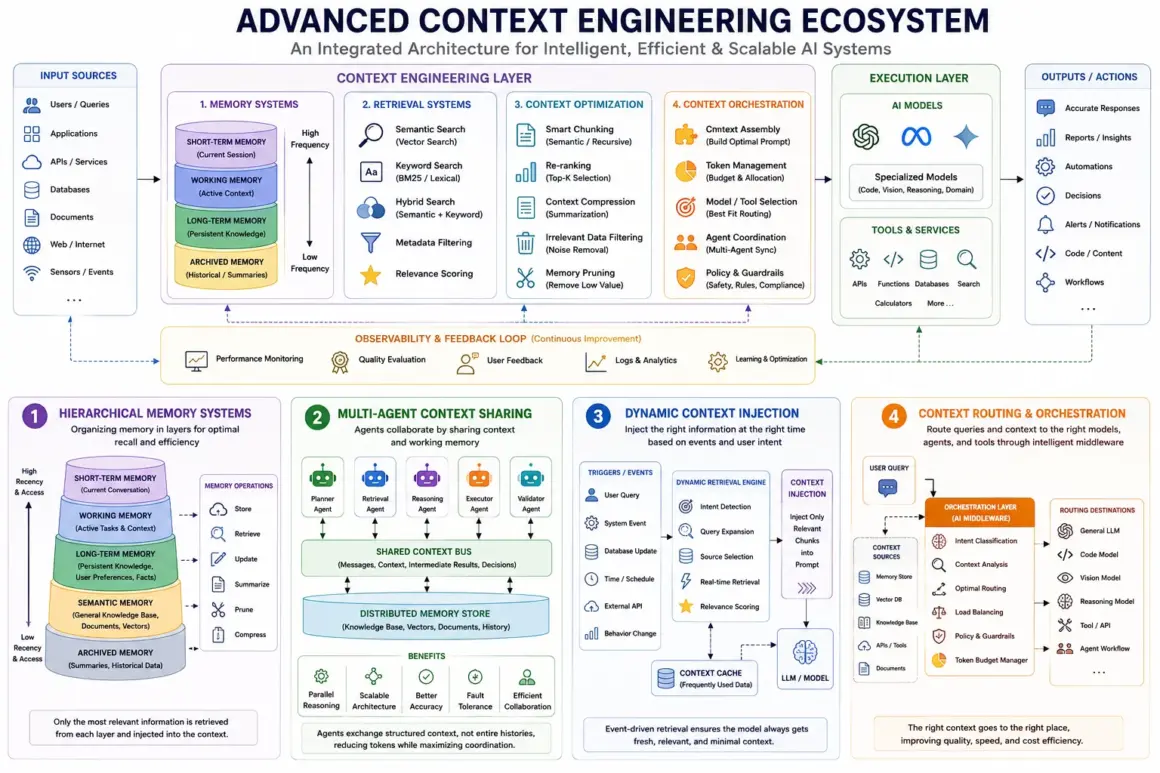
These techniques allow AI systems to maintain continuity across conversations, collaborate across agents, retrieve relevant information dynamically, and intelligently route tasks to specialized models or tools. In many ways, advanced context engineering is becoming the operating system layer for next-generation AI infrastructure.
Hierarchical Memory Systems
One of the biggest limitations of traditional LLMs is memory persistence.
Most models operate with temporary session memory, meaning they only retain information inside the active context window. Once tokens exceed the limit or the session ends, earlier knowledge disappears.
To solve this, modern AI systems increasingly use hierarchical memory architectures.
These systems organize memory into multiple layers based on importance, recency, and usage frequency.
Typically, hierarchical memory includes:
- Short-term working memory
- Long-term persistent memory
- Episodic interaction history
- Semantic knowledge storage
- Archived contextual memory
Short-term memory handles immediate conversational context such as recent instructions, active tasks, and temporary reasoning chains.
Long-term memory stores persistent information like user preferences, project history, workflows, organizational knowledge, or recurring patterns.
This layered approach improves continuity and personalization while reducing token overload.
For example, an enterprise AI assistant may temporarily retain the current conversation in short-term memory while storing employee preferences, company procedures, and historical interactions in long-term memory systems.
This type of AI memory architecture enables systems to behave more consistently across extended interactions.
Advanced memory pipelines also use:
- Memory summarization
- Context compression
- Priority scoring
- Retrieval-based recall
- Relevance-driven memory injection
Instead of continuously loading all previous data into the context window, the system selectively recalls only the most relevant information when needed.
This dramatically improves scalability and long-context efficiency.
Multi-Agent Context Sharing
Another major advancement in context engineering is the rise of multi-agent systems.
Instead of relying on one giant AI model to perform every task, developers increasingly build systems composed of specialized AI agents working collaboratively.
For example:
- One agent handles retrieval
- Another performs reasoning
- A third validates outputs
- Another executes tools or APIs
- A planning agent coordinates workflows
This architecture is central to modern agentic AI systems.
However, collaborative AI introduces a new challenge: context sharing.
Each agent needs access to relevant memory, task state, retrieved documents, and reasoning outputs without overwhelming the system with unnecessary information.
To solve this, advanced platforms use distributed context-sharing mechanisms where agents exchange structured contextual summaries instead of raw conversation history.
This creates several benefits:
- Reduced token consumption
- Better task specialization
- Improved reasoning quality
- Parallel problem solving
- Scalable AI workflows
Some systems even implement distributed memory layers where agents write to shared knowledge stores accessible across the architecture.
For example, in a software engineering workflow:
- A retrieval agent searches documentation
- A coding agent generates implementation logic
- A testing agent validates outputs
- A review agent checks security and quality
All agents operate using synchronized contextual memory.
This collaborative reasoning model is becoming increasingly important for enterprise automation and autonomous AI systems.
Dynamic Context Injection
Traditional prompting relies on static inputs. Advanced AI systems instead use dynamic prompting techniques that inject information in real time based on the current task, user intent, or external events.
This process is known as context injection.
Instead of loading all available information into the prompt, the system intelligently decides:
- What information matters
- When it should appear
- How long it should persist
- Which sources are most relevant
This dramatically improves efficiency and response quality.
For example, a customer support AI may dynamically retrieve:
- User account history
- Product documentation
- Recent support tickets
- Real-time system outages
- Subscription details
only when required.
This is often powered by event-driven retrieval systems that trigger contextual updates based on specific actions or conditions.
Examples include:
- User behavior changes
- External API updates
- New database records
- Workflow state transitions
- Time-sensitive events
Dynamic injection prevents unnecessary token waste while ensuring the model receives highly relevant information exactly when needed.
This approach is particularly important in long-running workflows, autonomous agents, and enterprise copilots where context changes continuously.
Context Routing & Orchestration
As AI ecosystems grow more complex, many organizations now use multiple models, tools, retrievers, and memory systems simultaneously.
This creates the need for intelligent AI orchestration layers.
Context orchestration engines act as middleware systems that coordinate:
- Retrieval pipelines
- Memory systems
- Tool execution
- Agent communication
- Prompt assembly
- Model selection
- Context prioritization
One critical capability is context routing.
Instead of sending every query to the same model, orchestration systems route requests dynamically to specialized components.
For example:
- Coding queries → code-specialized LLM
- Legal analysis → compliance-tuned model
- Search-heavy tasks → retrieval pipeline
- Multi-step reasoning → agent workflow engine
This improves cost efficiency, response quality, and system scalability.
Modern AI middleware platforms also manage token budgets across multiple pipelines, ensuring context windows remain optimized without losing critical information.
In enterprise environments, orchestration layers increasingly function as the central nervous system of AI infrastructure.
Rather than viewing AI as a single chatbot, organizations now build interconnected ecosystems where retrieval systems, memory layers, agents, tools, and models work together through intelligent context management.
This is why advanced context engineering is rapidly becoming one of the most important disciplines in next-generation AI system design.
Common Problems in Long Context & RAG Systems
Long-context AI models and Retrieval-Augmented Generation (RAG) systems have significantly improved the capabilities of modern AI applications. They enable models to process massive documents, retrieve external knowledge, and maintain richer conversational memory. However, these systems are far from perfect.
As organizations deploy AI at scale, several technical and architectural challenges continue to emerge. Even advanced retrieval pipelines can produce inaccurate outputs, inefficient responses, and security vulnerabilities if context management is poorly designed.
Understanding these limitations is essential for building reliable enterprise-grade AI systems.
Hallucinations Despite RAG
One of the biggest misconceptions about RAG systems is that retrieval completely eliminates hallucinations.
In reality, RAG hallucinations still occur frequently.
The primary reason is retrieval mismatch. A retriever may return documents that are only partially relevant, outdated, or semantically similar but factually incorrect for the specific query.
For example, a legal AI assistant may retrieve clauses from the wrong jurisdiction, or a coding assistant may surface outdated API documentation. The language model then generates an answer based on flawed context, producing confident but inaccurate outputs.
Another major issue is poor chunk quality.
If documents are chunked incorrectly, important context may become fragmented across multiple sections. Small chunks can lose semantic meaning, while oversized chunks may contain too much irrelevant information.
This creates several retrieval errors, including:
- Missing critical context
- Injecting unrelated information
- Redundant retrieval
- Contradictory knowledge sources
Even if the correct information exists inside the database, weak retrieval ranking or poor chunk structure can prevent the model from accessing it effectively.
This is why retrieval quality often matters more than raw database size.
Context Poisoning
As AI systems gain access to larger external knowledge sources, another serious challenge emerges: context poisoning.
Context poisoning happens when irrelevant, misleading, malicious, or low-quality information contaminates the model’s context window.
This can occur accidentally through noisy datasets or intentionally through adversarial attacks.
Examples include:
- Spam documents inserted into vector databases
- Manipulated retrieval content
- Conflicting instructions hidden inside documents
- Low-quality web data
- Prompt injection attacks
- Unauthorized internal data exposure
These issues create major AI security concerns, especially in enterprise environments handling sensitive information.
For instance, if a retrieval system indexes unverified documents, an attacker could intentionally insert malicious instructions designed to manipulate model behavior during retrieval.
Since LLMs heavily depend on contextual information, poisoned context can influence reasoning, override instructions, or distort outputs.
To reduce context poisoning risks, organizations increasingly implement:
- Source verification
- Access controls
- Metadata filtering
- Retrieval validation
- Content sanitization
- Trust scoring systems
Security-aware context engineering is becoming a critical requirement for production AI systems.
Latency and Scalability Issues
As RAG systems grow larger, performance bottlenecks become increasingly difficult to manage.
One major challenge is retrieval latency.
Large-scale vector searches across millions — or even billions — of embeddings require substantial computational resources. Complex semantic search pipelines, re-ranking systems, and multi-stage retrieval workflows can slow response generation significantly.
This becomes especially problematic in real-time applications like:
- AI copilots
- Customer support assistants
- Autonomous agents
- Enterprise search platforms
Another issue is vector database scaling.
As document collections grow, infrastructure complexity increases rapidly. Systems must handle:
- High-volume indexing
- Continuous embedding updates
- Distributed retrieval workloads
- Real-time synchronization
- Multi-tenant access control
These scalability pressures increase operational costs and engineering complexity.
Additionally, long-context models themselves introduce inference overhead. Larger context windows require more transformer attention computation, increasing GPU memory usage and slowing response times.
Solving these AI scalability challenges requires advanced optimization strategies such as:
- Hybrid retrieval pipelines
- Efficient indexing
- Context compression
- Token budgeting
- Caching systems
- Distributed vector infrastructure
Ultimately, building scalable long-context AI systems is not just a model problem — it is a systems engineering challenge that depends heavily on intelligent context architecture.
Best Practices for Context Engineering
Building reliable AI systems is no longer just about choosing a powerful language model. The quality of an AI application increasingly depends on how effectively it manages retrieval, memory, token allocation, and contextual relevance. Even advanced models can produce poor outputs if the surrounding context pipeline is poorly designed.
This is why modern context engineering best practices focus heavily on optimizing information flow before generation occurs.
One of the most important strategies is using hybrid retrieval instead of relying solely on semantic vector search.
Semantic retrieval is excellent for understanding meaning, but it may struggle with exact keywords, technical identifiers, product codes, or domain-specific terminology. Hybrid retrieval combines semantic search with traditional keyword-based ranking methods like BM25 to improve precision and recall simultaneously.
Another critical best practice is keeping document chunks meaningful.
Poor chunking remains one of the biggest causes of retrieval failure in RAG systems. Chunks that are too small lose context, while oversized chunks introduce unnecessary noise into the prompt window.
Effective chunking strategies should preserve semantic coherence by splitting documents around:
- Topic boundaries
- Paragraph structure
- Headings and sections
- Logical reasoning units
Semantic and recursive chunking methods usually outperform fixed token splitting for enterprise-scale systems.
Equally important is relevance scoring.
Not all retrieved information deserves equal priority. Advanced AI systems rank retrieved chunks using similarity scores, metadata weighting, freshness indicators, and contextual relevance signals before injecting them into the prompt.
This dramatically improves response accuracy while reducing context dilution.
Modern AI architectures also benefit heavily from maintaining a structured memory hierarchy.
Instead of forcing all information into a single context window, systems should separate:
- Short-term working memory
- Long-term persistent memory
- Archived historical memory
- Session-specific retrieval context
This layered structure improves personalization, reasoning continuity, and token efficiency simultaneously.
Another major best practice is continuous retrieval evaluation.
Many organizations incorrectly assume retrieval pipelines work well once deployed. In reality, retrieval quality degrades over time due to evolving data, changing user behavior, outdated embeddings, and scaling complexity.
Production AI systems should continuously monitor:
- Retrieval precision
- Recall quality
- Hallucination rates
- Context relevance
- Latency metrics
- User satisfaction
Teams increasingly use automated evaluation pipelines and synthetic benchmark testing to measure AI system performance consistently.
Monitoring token budgets is equally essential.
Large prompts increase inference cost, latency, and attention inefficiency. Advanced systems dynamically compress, summarize, filter, and re-rank context before generation to maximize information quality per token.
Finally, organizations should implement standardized evaluation benchmarks for retrieval quality, reasoning accuracy, memory persistence, and response consistency.
The future of RAG optimization will depend less on raw model size and more on how intelligently systems manage contextual information at scale.
Real-World Use Cases of Context Engineering
Context engineering is rapidly becoming a foundational layer for production AI systems across industries. Modern AI applications no longer operate as standalone chatbots — they function as intelligent systems connected to memory architectures, retrieval pipelines, enterprise knowledge bases, and real-time external data sources.
As AI adoption grows, context-aware architectures are enabling more reliable, scalable, and specialized applications.
Enterprise AI Assistants
One of the largest use cases for context engineering is enterprise AI assistants.
Large organizations generate enormous amounts of internal information across documents, emails, databases, support systems, wikis, APIs, and collaboration platforms. Traditional search systems often struggle to surface relevant knowledge quickly.
Context-engineered AI assistants solve this by combining:
- Retrieval-Augmented Generation (RAG)
- Long-term organizational memory
- Role-based access control
- Semantic enterprise search
- Dynamic context injection
These systems can retrieve company policies, technical documentation, project histories, meeting notes, and workflow procedures in real time.
For example, an employee could ask:
“Summarize our latest cybersecurity compliance changes for the finance department.”
The AI system dynamically retrieves the relevant internal documents, ranks the most important sections, and generates a concise contextual answer.
This dramatically improves productivity and knowledge accessibility across organizations.
AI Coding Assistants
Modern AI coding assistants rely heavily on advanced context engineering techniques.
Writing code is not just about generating syntax — it requires understanding repository structure, architecture patterns, dependencies, APIs, documentation, and historical implementation decisions.
Simple prompts are not enough for this level of reasoning.
AI coding systems therefore use:
- Repository-level retrieval
- Long-context memory
- Code embeddings
- Dependency-aware chunking
- File relationship mapping
This enables AI systems to reason across entire codebases rather than isolated snippets.
For example, a coding assistant may retrieve:
- Relevant files
- Function definitions
- API references
- Architecture documentation
- Historical bug fixes
before generating implementation suggestions.
This contextual awareness dramatically improves code accuracy, debugging capability, and multi-file reasoning.
Healthcare & Legal AI
Industries like healthcare and legal services require highly accurate contextual reasoning across extremely large documents.
Medical AI systems often analyze:
- Patient histories
- Clinical notes
- Research literature
- Diagnostic reports
- Treatment guidelines
Similarly, legal AI platforms process:
- Contracts
- Case law
- Compliance policies
- Regulatory frameworks
- Litigation records
These domains require sophisticated retrieval precision because incorrect context can produce severe consequences.
As a result, healthcare and legal AI systems rely heavily on:
- Compliance-sensitive retrieval
- Source verification
- Metadata filtering
- Long-document summarization
- Context ranking
- Hallucination reduction pipelines
Advanced context engineering helps ensure that generated outputs remain grounded, traceable, and contextually accurate.
AI Research Systems
Research-focused AI systems are another major application area.
Researchers increasingly use AI tools to summarize academic papers, synthesize findings across multiple studies, identify knowledge gaps, and accelerate literature review workflows.
These systems depend heavily on context orchestration because scientific reasoning often requires combining information from many different sources simultaneously.
Modern research AI platforms use:
- Multi-document retrieval
- Semantic clustering
- Citation-aware ranking
- Knowledge graph integration
- Long-context reasoning
This allows AI systems to generate structured summaries and identify conceptual relationships across large research corpora.
As enterprise AI applications continue evolving, context engineering will increasingly become the core infrastructure layer that enables scalable, trustworthy, and domain-specific AI systems across industries.
Future of Context Engineering in AI
The future of artificial intelligence will not be defined only by larger models or more parameters. Increasingly, the real competitive advantage is shifting toward memory, retrieval quality, contextual reasoning, and orchestration intelligence. This is why context engineering is rapidly becoming one of the most important architectural layers in modern AI systems.
One major trend shaping the long-context AI future is the rise of million-token context windows.
AI companies are continuously expanding how much information models can process at once. Future systems may analyze entire books, large code repositories, enterprise databases, or years of conversational history within a single context window.
However, larger windows alone are not enough.
As context size grows, systems must intelligently prioritize information, reduce noise, compress memory, and optimize retrieval quality. This will accelerate the development of more advanced context orchestration frameworks capable of dynamically managing massive information environments.
Another major shift involves memory-native AI systems.
Today’s AI models still operate mostly as stateless systems that rely on temporary context windows. Future architectures are expected to integrate persistent memory directly into the reasoning process.
These systems may continuously learn user preferences, workflows, historical interactions, and long-term objectives across sessions.
This evolution could enable highly personalized AI assistants capable of functioning more like long-term collaborators rather than isolated chatbots.
The future also points toward increasingly autonomous retrieval systems.
Instead of waiting for explicit prompts, AI agents may proactively retrieve information, monitor changing environments, update memory hierarchies, and dynamically optimize context in real time.
This capability is central to the evolution of agentic AI.
Future AI ecosystems will likely involve multiple specialized agents collaborating through shared memory systems, orchestration engines, and distributed contextual reasoning pipelines.
For example:
- Planning agents may coordinate workflows
- Research agents may retrieve external knowledge
- Reasoning agents may validate decisions
- Execution agents may interact with APIs and tools
All while continuously synchronizing contextual state.
Another important trend is personalized AI memory.
Future AI systems may maintain long-term contextual profiles for individual users, organizations, and workflows while respecting privacy and access controls. This would allow AI assistants to understand preferences, communication styles, recurring tasks, and domain-specific knowledge over time.
Ultimately, the future of AI memory is moving toward systems that can reason, retrieve, adapt, and collaborate dynamically across large-scale contextual environments.
Context engineering is no longer just an optimization technique — it is becoming the foundational infrastructure layer for next-generation AI systems.
Summary
As AI systems become more powerful, the challenge is no longer just generating text — it is managing information intelligently.
This is why context engineering has emerged as one of the most important disciplines in modern artificial intelligence. From long-context reasoning and memory management to Retrieval-Augmented Generation (RAG), orchestration layers, and dynamic retrieval pipelines, context engineering determines how effectively AI systems understand, prioritize, and use information.
Traditional prompt engineering focused primarily on crafting better instructions. But modern AI applications require far more sophisticated architectures capable of handling massive contextual environments efficiently.
Throughout this guide, we explored:
- Long context windows
- Token optimization
- RAG architectures
- Memory systems
- Context orchestration
- Multi-agent collaboration
- Retrieval optimization
- Enterprise AI workflows
Together, these technologies are redefining how intelligent systems operate.
Organizations building AI applications today must move beyond static prompting and focus on scalable AI context management strategies that improve accuracy, reduce hallucinations, optimize costs, and enhance reasoning quality.
The future of AI will increasingly depend on smarter retrieval systems, better memory architectures, and more advanced context orchestration engines.
In many ways, the next generation of AI innovation will not come solely from larger models — it will come from better context engineering.
FAQ Section
1. What is context engineering in AI?
Context engineering is the process of managing and optimizing the information an AI model receives before generating a response. It includes retrieval systems, memory management, prompt assembly, ranking, filtering, and token optimization.
For example, a customer support AI may retrieve user history, product documentation, and real-time account data before answering a query.
2. How is context engineering different from prompt engineering?
Prompt engineering focuses on writing effective prompts for AI models.
Context engineering operates at a broader system level. It manages memory, retrieval pipelines, context ranking, token allocation, orchestration, and dynamic information injection across the entire AI workflow.
In short:
- Prompt engineering = better instructions
- Context engineering = better information systems
3. What are long context windows in LLMs?
A long context window refers to the amount of text an AI model can process at one time.
Modern LLMs can handle thousands or even millions of tokens, allowing them to analyze long documents, large conversations, and complex datasets within a single interaction.
Longer context windows improve memory retention and multi-step reasoning but also introduce challenges like latency, token inefficiency, and context dilution.
4. What is a RAG system?
A RAG (Retrieval-Augmented Generation) system combines external information retrieval with AI text generation.
Instead of relying only on training data, the system retrieves relevant documents from vector databases or knowledge sources and injects them into the prompt before generation.
This helps improve factual accuracy and reduces hallucinations.
5. Why do AI models hallucinate even with RAG?
Hallucinations can still happen because retrieval systems may return incorrect, outdated, or poorly ranked information.
Other causes include:
- Weak chunking strategies
- Retrieval mismatch
- Context overload
- Poor relevance scoring
- Noisy or low-quality data
RAG improves accuracy, but retrieval quality and context management remain critical.
6. How can token optimization reduce AI costs?
Token optimization reduces the number of unnecessary tokens processed by the model.
This lowers:
- API costs
- GPU computation
- Inference latency
- Memory usage
Techniques like semantic chunking, summarization, filtering, compression, and relevance ranking improve efficiency while maintaining response quality.